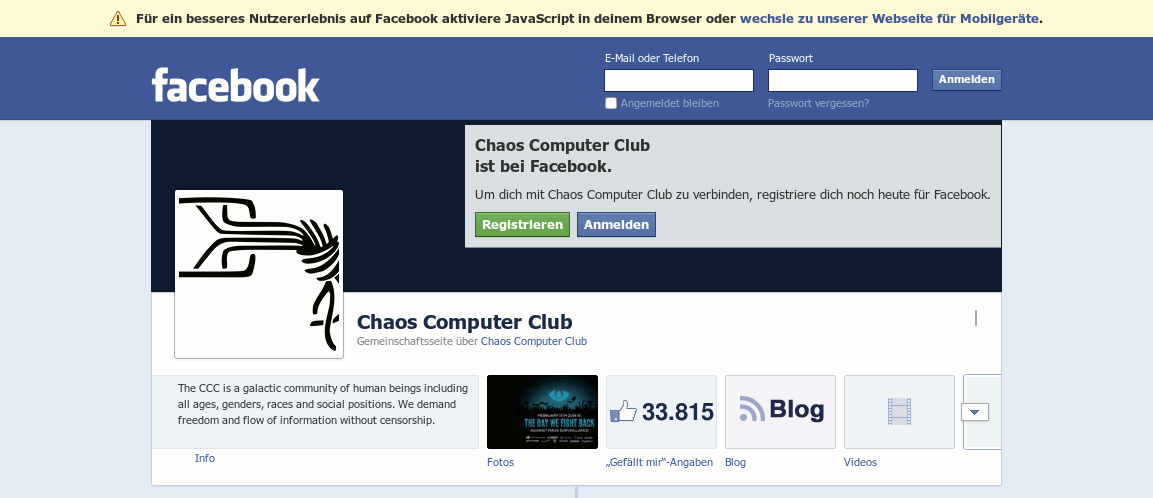
Sehr wichtiger Nachtrag vom 16. Juni
Der folgende Rant bezieht sich auf eine Facebook-Seite, die nicht vom Chaos Computer Club betrieben wird. Es gibt keine Facebook-Seite des CCC. Jede Facebook-Seite, die behauptet vom CCC zu stammen, ist eine Fälschung. Da ich es – auch wegen des täuschend »guten« Facebook-Auftrittes irgendwelcher Gestalten, die sich zum Einsammeln von Followern einfach CCC nennen – unterlassen habe, einfach mal beim CCC anzufragen und meinem pawlowschen Facebook-Speichelfluss freien Lauf gelassen habe, ist ein Rant entstanden, der die Falschen trifft. Näheres bitte den Kommentaren zu diesem Text entnehmen.
Mein ursprünglicher Text bleibt hier – um den Kontext nicht zu zerstören – zu Archivzwecken und zu meiner Schande unverändert stehen:
Nicht, dass ich euch als Nicht-Mitglied belästigen möchte, aber eines muss ich doch festhalten. Während ich durch die Welt ziehe und jedem Menschen irgendwann einmal sage, wie überwältigend wichtig ein Mindestmaß an digitaler Autonomie – als das Gegenteil von social media, cloud und anderen Vermarktungen und Enteignungen – in der gegenwärtigen Zeit ist, setzt ihr euch hin und macht das hier¹:
33.815 Leuten gefällt das.
Mir gefällt das nicht.
Und euch beim CCC sollte es eigentlich auch nicht gefallen, einen Beitrag dazu zu leisten, dass Facebook seine meiner Meinung nach entbehrliche Website durch eure freiwillige, unbezahlte und aktive Mitwirkung noch ein bisschen attraktiver hat. Ja, dieses Facebook, das ein Spammer ist, der übrigens auch klandestin über die Wischofon-App eingesammelte Mailadressen mit Spam zuscheißt. Dieses Facebook, das Spammethoden auch intern anwendet und Vorschläge in fremden Namen ausspricht (siehe auch hier oder hier). Dieses Facebook, das nicht nur technokratisch durchgesetzte Regeln gegen allzu freies Kommentieren hat, sondern auch nicht vor offener politischer Zensur zurückschreckt (siehe auch hier oder etwas fragwürdiger hier). Dieses Facebook, das keine Hemmungen hat, seine Nutzer dazu aufzufordern, das gesamte Web mit dem so genannten »Like-Button« in eine Tracking-Engine für die Datensammlung eines börsennotierten Unternehmens ohne seriöses Geschäftsmodell umzuwandeln² und früher, bis das mal aufgeflogen ist, durch spezielle Programmierung dafür Sorge trug, dass das Tracking auch bei scheinbar »ausgeloggten« Nutzern möglich blieb – von den Implikationen in Form des patriot act und der klandestinen Weltüberwachungsambitionen der Vereinigten Staaten eines Teils von Nordamerika will ich bei dieser Idee gar nicht erst reden. Dieses Facebook, das Wischofone weitgehend verwanzt und mit den so eingesammelten Überwachungsdaten ein Businessmodell durch Profilbildung anhand der installierten Apps errichten will. Dieses Facebook, das – wenn es sich schon auf dem Handy austoben kann – auch gleich die dort gespeicherten persönlichen Adressbücher des Nutzers manipulieren wollte und hinterher von einem bedauerlichen Fehler sprach, ganz so, als ob Programmcode zum Bearbeiten der Adressbuch-Datenbank sich neuerdings von alleine schriebe. Dieses Facebook, das seine Datensammlung so vermarkten will, dass Werber daran ihre Mailadressen und Telefonnummern abgleichen können. Dieses Facebook, das sich auf dem Standpunkt stellt, dass es eine Verschwendung von Steuergeldern ist, Datenschutz durch anonyme oder pseudonyme Nutzungsmöglichkeiten einzufordern und folgerichtig »Freunde« seiner Nutzer kurzerhand als kostenlose und diensteifrige Klarnamens-Blockwarte einspannt. Dieses Facebook, das die eingesammelten Daten mal eben durch irgendwelche externen Unternehmen auswerten lässt. Dieses Facebook, das eingesammelte Daten als sein »Geistiges Eigentum« betrachtet und das seinen »Datenschutz« so gestaltet, dass der Verbraucherzentrale Bundesverband ausdrücklich von einer Nutzung abrät, was ich angesichts der stetigen Verschlimmerung der Zustände für einen weisen Rat halte³…
Nun, ihr beim CCC scheint diesen Rat für nicht ganz so weise zu halten. Ihr seid halt ein deutscher Verein; ihr kommt aus dem Land, in dem Google Fassaden verpixeln muss, wärend Facebook – natürlich ohne dass Nutzer so etwas erst umständlich freischalten müssen, denn man ist ja bequem – biometrische Datenbanken zur Gesichtserkennung aufbaut (sicherlich auch zugunsten der Horch- und Morddienste der USA).
Dass ihr ganz offiziell bei Facebook – von mir meist »liebevoll« als »Fratzenbuch« bezeichnet – seid, ist das genaue Gegenteil aller Dinge, für die ihr sonst lobenswerterweise einsteht. Ihr seht in dieser realsatirisch wertvollen Geste so aus wie ein Tierschützer, der im Pelzmantel für den Tierschutz demonstriert.
Was meint ihr, wie ich euer Facebook-Profil gefunden habe?
Nein, ich bin nicht selbst auf die Idee gekommen, danach zu suchen, weil ich die Vorstellung für absurd gehalten hätte. Ich habe es gefunden, als ich heute morgen einer Zeitgenossin – nennen wir sie mal Birgit – ein paar Kleinigkeiten erklärt habe, damit sie auf diesem Überwachungsplaneten ein bisschen zum Schutz ihrer Privatsphäre tun kann. Ich habe ihr gezeigt, wie man E-Mail verschlüsselt, wie man Tor benutzt, wie man Jabber mit OTR benutzt, welche Browsereinstellungen – zum Beispiel das Ablehnen von Drittanbieter-Cookies – empfehlenswert sind und wie man essentielle Plugins wie »NoScript« im Browser installiert. Und ich habe ihr auch empfohlen, ihren Account bei Facebook stillzulegen, den wertvolleren Kontakten eine E-Mail-Adresse zuzustecken oder sie in ein anderes Netzwerk zu »locken«. Birgit sagte dazu allerdings nur: »Wieso denn das, der CCC ist doch auch bei Facebook«.
Birgit war nämlich eine von den 33.815 Leuten, denen das gefiel.
Deshalb habe ich euch gesucht. Ich habe das für einen Witz gehalten. Und. Ich musste feststellen, dass es kein Witz war.
Und nicht nur das: Der Facebook-Account ist kein Platzhalter, sondern gut gepflegt. Die letzte öffentliche Meldung ist von vorgestern. Das Dingens wird nicht nur »so nebenbei« betrieben. Es sieht ganz anders aus als eure »CCC Updates« [sic! Mit Deppen Leer Zeichen…] im dezentralen Diaspora-Netzwerk, wo die letzte Meldung vom 5. März ist.
Man könnte beinahe denken, dass ihr beim CCC Dezentralität für eine schlechte Sache haltet, zentral organisierte Datenstaubsauger der Marke »Facebook« aber gern mit euren Daten füttert.
Ob dieser sich – vermutlich nicht nur mir – bei bloßer Betrachtung eures Tuns aufdrängelnde Gedanke wohl kompatibel zu irgendeinem Ziel des CCC ist?
Wenn ihr beim CCC meint, dass er das ist, dann macht einfach so weiter!
Und ansonsten: Seht zu, dass ihr vom Fratzenb von Facebook wegkommt! Es ist nicht gut, dort zu sein. Und es ist gut, nicht mehr dort zu sein.
Fußnoten
¹Als Screenshot belegt, weil ich vermeiden will, diese Website zu verlinken.
²Der so genannte »Like-Button« ist nicht nur eine Tracking-Wanze für große Teile des Web, sondern in meinen Augen auch ein Hilfsmittel für Menschen, die zu doof geworden sind, die in der Adressleiste angezeigte URI über die Zwischenablage in eine TEXTAREA zu kopieren. Er ist ein Hilfsmittel zur Ausbreitung des Computer-Analphabetismus, um auf Grundlage dieser künstlich geschaffenen Beeinträchtigung fragwürdige Businessmodelle vorantreiben zu können.
³Die Texte sind alt. Der Zustand nicht.